Experimental Medicine Application Platform (EMAP)
EMAP is a translational data science platform built in and for the NHS and has been specifically created to support research. It contains over 100 million health data items from UCLH, with 500 items added every minute, and has been developed as a non-operational “mirror” of a subset of UCLH data (historical and live). The underpinning aim is to ensure that no clinical data are corrupted or destroyed during the interaction between the research process and the hospital’s systems and that the systems are not compromised (for instance, if they are interrupted or slowed down by research enquiries).
Today, the typical way for a researcher to access hospital data is to extract it from the hospital into the outside world. This introduces privacy risks, as the data leave the protected environment of the NHS. EMAP reverses this process. By providing a software environment within the hospital, we enable research to happen inside the NHS, so that patient data never have to leave.
Currently, EMAP includes demographics, vital signs, lab tests and more, and consists of:
- a live data warehouse
- a secure research environment giving ready access to modern data science and software development tools
- access to powerful and flexible compute facilities.
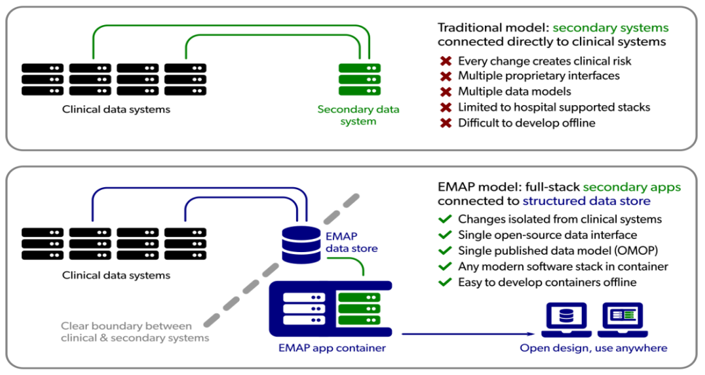 Data are transmitted live from the Epic, UCLH’s new electronic health record system (EHRS), by means of HL7 interfaces (a set of international standards for transfer of clinical and administrative data between software applications used by various healthcare providers), supplemented by standard ETL (“extract, transform, load”) pipelines, where appropriate. Additionally, data from legacy systems have been transferred into a “data lake”, a repository that holds vast amounts of raw data until needed.
Data are transmitted live from the Epic, UCLH’s new electronic health record system (EHRS), by means of HL7 interfaces (a set of international standards for transfer of clinical and administrative data between software applications used by various healthcare providers), supplemented by standard ETL (“extract, transform, load”) pipelines, where appropriate. Additionally, data from legacy systems have been transferred into a “data lake”, a repository that holds vast amounts of raw data until needed.
Data within the warehouse are modelled in a tiered series of databases optimised for different use cases, culminating in data coded using SNOMED-CT (a structured clinical vocabulary for use in an electronic health record), and modelled using the OMOP format to aid interoperability. A FHIR interface is currently in development.
EMAP is one of the workstreams of the INFORM project, initially funded by the UCLH Charity and supported by the UCLH/UCL BRC. The development of EMAP at UCLH has been led by Dr Mark White (UCLH Chief Technology Officer) in conjunction with Drs Steve Harris, Tim Bonnici, Dave Brealey and Niall MacCallum.
Why was EMAP developed
The potential for data-driven products – analytics, algorithms and apps – to improve health care is widely recognised. However, despite an explosion in the number of digital health papers being published, very few innovations make it out of the lab to the bedside. Similarly, the creative potential of frontline NHS staff remains largely untapped because of the difficulties using data for innovation within their own hospitals.
A number of barriers stand in the way:
- Routinely-collected clinical data are “siloed”, "dirty" and difficult to access.
- Modern tools and compute are not routinely available within the NHS firewall, where the data rest. Exporting the data means grappling with the increasingly thorny issues of patient privacy, information security and data governance.
- Live data to drive real-time apps and clinical decision support are not readily available. Even where they are, utilising them requires in-depth knowledge of the hospital infrastructure and arcane messaging standards. This makes it hard for innovators to develop applications and evaluate their real-world effect with the same rigour in which we expect drugs to be evaluated.
- There is no safe space for experimentation using live data. The need to protect the operational integrity of clinical information systems is at odds with the innovation process, which inevitably involves iteration, blind alleys and mistakes.
Beyond the technological barriers, there are skills and data-literacy barriers. The staff delivering patient care day in day out are well placed to understand where digitally-enabled change would be useful but they may not have the knowledge or skills to translate their ideas into effective and sustainable technological innovation.
OMOP
We are participating in, and leading, many studies based on the OHDSI/OMOP Common Data Model (CDM). This includes EHDEN and HIC projects.
Doing this allow us to collaborate internationally based on large scale, standardised data sets and open source analytic workflows.
To enable this, our OMOP data extraction pipeline, aka OMOP ES, was constructed.
This allows a diverse range of data and systems to be mapped to OMOP in a controlled, governed manner – with rules to anonymise and redact data so as to respect the privacy of patients.
The extraction pipeline was designed to easily allow new types of data to be incorporated, enforce high quality mapping and be portable to other EPIC sites.
The team behind this is made up of data engineers, clinical domain experts, system integration engineers and experts on data standards.
We’re proud of what we have produced and are happy to share our experiences and learnings with our counterparts in other BRCs, Trusts, and the world!
The CogStack platform is a clinical text analytics platform that provides a set of software tools for facilitating the extraction and retrieval of information from free-text documents (e.g. GP and referral letters, medical reports, etc.) using standardised terminologies.[1] The platform was originally developed at King’s College London, and further supported by the CRIU at UCL/UCLH BRC. It uses enterprise search, natural language processing (NLP),[2,3,4,5,6] analytics and visualisation technologies to allow both structured and unstructured data in electronic health records (EHRs) to be unlocked and used to assist in clinical decision-making and clinical research.

The need
It is estimated that as many as 80% of the world's data is unstructured, with businesses only able to use a portion of this data. Similarly, EHRs are often incomplete, containing large quantities of unstructured data, stored in proprietary systems and in different formats.
Being able to ‘structure’ the unstructured parts of the EHRs is a challenge, especially at large NHS trusts such as UCLH which have many years’ worth of EHRs stored in various systems and in various formats. Before being able to analyse the unstructured data, the first challenge is being able to quickly access all the records in the Trust. The CogStack platform has been useful in this regard, as through its data ingestion tools it has been possible to set up data pipelines to ingest nearly all of the trust’s EHR in a way that is scalable and robust.
The primary goal of CogStack is to facilitate better point-of-care decisions as well as support important clinical research. To this end CogStack has a number of NLP tools that are capable of extracting and reporting important clinical concepts from free text. One of the most used NLP models in the CogStack toolset is Medcat,[5,10] a machine learning model that can extract clinical concepts from free text notes. In addition, the CogStack platform has been used to train other NLP models.
CogStack in action
CogStack has been a key part of a number of clinical research initiatives within the NHS sites that have deployed it. Below are a few:
- It has enabled free-text search for EHRs and identification of relationships between entities in the text, as well as timely risk monitoring and alerting.[1]
- It has led to improved efficiency in the clinical trials recruitment process.[2,3]
- It has been used to detect reasons/causes for allergic reactions for prescribed and/or administered medications within the NHS national allergy reporting database.
- It has been employed as part of a number of cohort studies. For example, it was used to speed up analysis in understanding the relationship between ACE-inhibitors and patients with Covid-19.[9]
- It has helped identify key patient pathways associated with A&E performance.[7]
- It has enabled NLP-assisted approaches to patient recruitment into trials with traditional manual approaches with a focus on the LeoPARDS trial.[8] The findings show that analysis of EHRs incorporating NLP tools could effectively replicate recruitment in a critical care trial, and greatly reduce the patient screening time vs manual revision by means of automated methods.
- CogStack provides the underlying technology for the Epic MiADE project, seeking to automate the process of filling in various clinical fields in the EHR system.
CogStack has also been used to routinely help automate the extraction of various data items for other projects such as the critical care theme of the Health Informatics Collaborative (HIC) at UCLH.
Into the future
Cogstack is also involved in a number of collaborations with clinics at the National Hospital for Neurology and Neurosurgery. It is being used to develop systems to recommend and fast track patients into these clinics based on the content of their EHRs (e.g. referral letters, imaging reports) so as to ensure the patients can potentially receive treatment that is timely and effective. Examples of this include the motor neuron disease clinic and the normal pressure hydrocephalus clinics.
In addition, CogStack NLP capabilities are currently being integrated into Find A Study, the UCLH platform enabling clinicians and patients to find clinical trials.
References
1. Jackson R et al. CogStack-experiences of deploying integrated information retrieval and extraction services in a large National Health Service Foundation Trust hospital. BMC medical informatics and decision making 2018; 18(47). doi: 10.1186/s12911-018-0623-9.
2. Wu H et al. SemEHR: Surfacing semantic data from clinical notes in electronic health records for tailored care, trial recruitment, and clinical research. The Lancet 2017; 390(S97). doi: 10.1016/S0140-6736(17)33032-5.
3. Wu H et al. SemEHR: A general-purpose semantic search system to surface semantic data from clinical notes for tailored care, trial recruitment, and clinical research. Journal of the American Medical Informatics Association 2018; 25(5):530–53. doi: 10.1093/jamia/ocx160.
4. Kraljevic Z et. al. MedCAT - Medical Concept Annotation Tool. arXiv 2019; 1912.10166. https://arxiv.org/abs/1912.10166
5. Searle T et al. MedCATTrainer: A biomedical free text annotation Interface with active learning and research use case specific customisation. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations 2019; D19-3024. doi: 10.18653/v1/D19-3024.
6. Gorrell G et al. Bio-YODIE: A named entity linking system for biomedical text. arXiv preprint arXiv 2018; 1811.04860. https://arxiv.org/pdf/1811.04860.pdf.
7. Bean DM et al. Network analysis of patient flow in two UK acute care hospitals identifies key sub-networks for A&E performance. PLOS ONE 12(10): e0185912. doi: 10.1371/journal.pone.0185912
8. Tissot H et al. Natural language processing for mimicking clinical trial recruitment in critical care: A semi-automated simulation based on the LeoPARDS trial. IEEE J Biomed Health Inform. 2020 Mar 9. doi: 10.1109/JBHI.2020.2977925. Epub ahead of print.
9. Bean DM, Kraljevic Z, Searle T, Bendayan R, O'Gallagher K, Pickles A, Folarin A, Roguski L, Noor K, Shek A, Zakeri R, Shah AM, Teo JTH, Dobson RJB. Angiotensin-converting enzyme inhibitors and angiotensin II receptor blockers are not associated with severe COVID-19 infection in a multi-site UK acute hospital trust. Eur J Heart Fail 2020 Jun;22(6):967-974. doi: 10.1002/ejhf.1924. Epub 2020 Jul 7.
10. Kraljevic Z, Searl T, Shek A, Roguski L, Noor K, Bean D, Mascio A, Zhu L, Folarin AA, Roberts A, Bendayan R, Richardson MP, Stewart R, Shah AD, Wong WK, Ibrahim Z, Teo JT, Dobson RJB., Bendayan R. Multi-domain clinical natural language processing with MedCAT: the Medical Concept Annotation Toolkit. Artificial Intelligence in Medicine 2021; doi: 10.1016/j.artmed.2021.102083.